Cockpit (panel de operación)¶
El Cockpit es el panel de observabilidad del ecosistema: muestra la conversión del autoservicio, el parque de terminales, la salud del backend, los tickets, los errores (por zona), los pagos y el estado fiscal. Es una SPA React que vive en cockpit-ui/ y la sirve el propio backend; los datos salen del módulo monitoring.
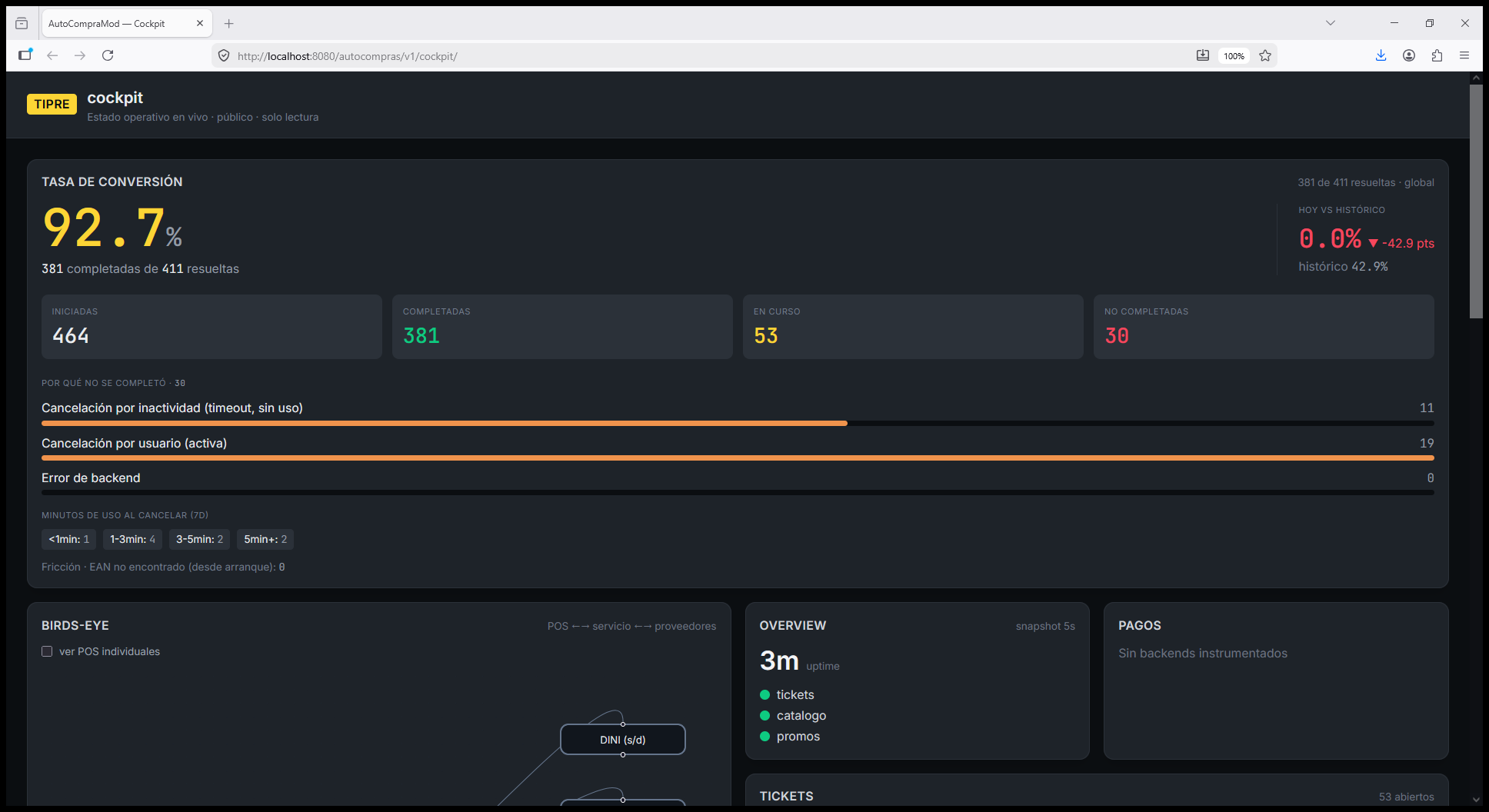
El Cockpit actual: el KPI de conversión (92.7% en oro) con las cards iniciadas/completadas/en curso/no completadas, el desglose "por qué no se completó" con sus labels, los "minutos de uso al cancelar" y la fricción EAN. Abajo arrancan el birds-eye, el overview (semáforos verdes) y pagos.
Cómo está montado¶
- Frontend:
cockpit-ui/— React 18 + TypeScript + Vite + Tailwind, con Recharts (gráficos) y ReactFlow (el "birds-eye"). - Tema "Binance-dark" (
cockpit-ui/tailwind.config.js): fondo near-black (#0b0e11), superficies#1e2329/#2b3139, acento oro (#fcd535) y semántica de trading verde (#0ecb81= OK/sube) / rojo (#f6465d= error/baja). Tipografía Inter (texto) + JetBrains Mono (números). - Build integrado: el profile
frontendde Maven instala Node local (frontend-maven-plugin), correnpm ci && npm run buildy copiadist/asrc/main/resources/static/cockpit. No es un deploy aparte. - Servido en:
/autocompras/v1/cockpit/—CockpitControllerhace fallback aindex.htmlpara el routing client-side. - Datos: el cliente HTTP (
cockpit-ui/src/api/client.ts) pega contra/autocompras/v1/monitoring/*, todoGET, sin auth. En dev, Vite proxyea ahttp://localhost:8080/autocompras/v1.
Snapshots, no queries por request
El módulo monitoring calcula snapshots periódicos con @Scheduled (refresco cada ~60 s) en vez de consultar la base en cada request del Cockpit. La instrumentación es aditiva y no bloqueante: observar el sistema no lo frena.
El KPI de conversión¶
Es el indicador estrella (plan 015): ¿qué porcentaje de las sesiones de autoservicio termina en una venta?
- Completadas =
CLOSE+PAGADO+VOUCHERPENDING(operaciones que llegaron a buen puerto). - Resueltas (denominador) = completadas + canceladas (usuario e inactividad) + errores de backend. Los tickets
OPEN(en curso) no entran;TEST/ANULADOtampoco.
Lo calcula MetricsSnapshotService.computeConversion() y viaja en el bloque conversion de GET /monitoring/tickets (record MetricsSnapshot.Conversion: rate, iniciadas, completadas, canceladasUsuario, canceladasInactividad, conError, enCurso, rateToday, rateBaseline, direction, cancelacionPorMinutos).
El ConversionPanel.tsx lo muestra como número grande en oro, con la tendencia de hoy vs. el baseline (verde si sube, rojo si baja), el desglose de por qué no se completó, y el histograma de minutos de uso al cancelar.
Por qué no se completó (motivos de cancelación)¶
El Cockpit distingue los motivos y los etiqueta:
| Estado | Label en la UI |
|---|---|
CANCELED_INACTIVITY |
"Cancelación por inactividad (timeout, sin uso)" |
CANCELED_USER |
"Cancelación por usuario (activa)" |
ERROR |
"Error de backend" |
Minutos de uso al cancelar¶
Para entender cuándo abandona la gente, las cancelaciones se bucketizan por cuánto duró la sesión antes de cancelar (TrxRepository.canceladasDuracionSince → bucketizeCancelDurations() en Java, ventana 7 días):
<1 min— abandono inmediato.1-3 min— uso muy breve.3-5 min— uso moderado.5 min+— uso sostenido (canceló tarde).
Fricción: EAN-no-existe¶
Aparte de la conversión está la fricción: cuando un cliente escanea un EAN que el catálogo no resuelve. No baja la conversión (el cliente re-escanea y cierra igual), pero es señal de catálogo incompleto. Se cuenta con un counter Micrometer selfservice.ean_not_found{sucursal} (incrementado en ArticuloService) y se expone en GET /monitoring/friction → { eanNotFound: { total, bySucursal } }.
Endpoints /monitoring/*¶
| Endpoint | Controller | Qué devuelve |
|---|---|---|
GET /monitoring/overview |
MetricsController |
Uptime, versión, semáforos de subsistemas con señal real (ver abajo). |
GET /monitoring/tickets?range=1d\|7d\|30d&codTerminal= |
MetricsController |
Totales por estado, serie temporal, drill-down por POS, KPI de conversión y tendencia. |
GET /monitoring/friction |
MetricsController |
(nuevo) EAN-no-existe por sucursal (acumulado desde el arranque). |
GET /monitoring/caches |
MetricsController |
Hit rate, estado (OK/EMPTY/STALE/DEGRADED) y próximo refresh de cada cache. |
GET /monitoring/api-calls |
MetricsController |
Top 50 endpoints por volumen — excluye el tráfico propio del Cockpit (/monitoring/**, /cockpit/**). |
GET /monitoring/errors?range=&page=&size= |
ErrorsController |
Errores paginados + resumen por categoría y por zona POS (byTerminal). |
GET /monitoring/terminals |
TerminalsController |
Parque reconciliado (configurados ∪ heartbeat) con device-health por terminal. |
GET /monitoring/payments |
PaymentsFiscalController |
Conteos por backend de pago (DINI / MP), vía Micrometer. |
GET /monitoring/fiscal |
PaymentsFiscalController |
AFIP, CAEA vigente, VOUCHERPENDING, backlog del reconciliador. |
GET /monitoring/jobs |
JobsController |
Estado de cada @Scheduled: última corrida, resultado, duración, próxima, conteos 24 h. |
GET /monitoring/jobs/history?name=&range= |
JobsController |
(nuevo) Historial paginado de un job puntual. |
Semáforos del overview: señal real¶
Antes los semáforos de subsistemas estaban hardcodeados a "up" (herencia de los microservicios). Ahora (MetricsController.overview()) cada uno refleja una señal real:
| Subsistema | Fuente | up | degraded | down |
|---|---|---|---|---|
tickets |
frescura del snapshot | ≤ 180 s | > 180 s | — |
catalogo |
estado de la cache articulos |
OK |
STALE/DEGRADED |
EMPTY |
promos |
estado de la cache promociones |
OK |
STALE/DEGRADED |
EMPTY |
En la UI (OverviewPanel): up → dot verde (OK), degraded → amarillo (WARN), down → rojo (ERROR).
El parque de terminales (reconciliado + heartbeat)¶
GET /monitoring/terminals no lista solo lo que pingeó: reconcilia las terminales configuradas con las que mandan heartbeat (TerminalFleetService.snapshot() = pos configuradas ∪ heartbeats vistos). Un POS puede estar en cuatro situaciones:
| Estado | Significa |
|---|---|
| Online | heartbeat fresco (online=true). |
| Offline conocido | se vio antes, ahora sin ping (lastSeen != null). |
| Nunca visto | configurado en pos pero sin un solo ping desde el arranque (lastSeen = null). |
| Huérfano | pingea sin estar en la tabla pos (configured=false). |
El parque configurado lo aporta tickets vía PosFleetFacade (en memoria, sin tocar la DB); si tickets no está, degrada con gracia (solo heartbeats). Un registro pasivo capta el ping de cada terminal en cada request; la ventana de "online" es ~90 s.
Device-health por POS (no global)¶
Cada terminal manda su salud de hardware en el header X-Device-Health (ej. pinpad=OK;point=UNKNOWN). El TerminalHeartbeatFilter lo parsea a un Map<device,status> y lo guarda en el heartbeat con preserve-on-null (un request sin el header no borra la última salud conocida). Esa salud es por terminal, no global.
Pinpad/Point salieron del birds-eye global
Antes el birds-eye mostraba "Pinpad: down" como si fuera un servicio global del sistema — era un falso negativo (el pinpad es hardware de cada POS). Ahora el pinpad/Point viven en el tile de cada terminal (chips verde OK / rojo OFFLINE / gris UNKNOWN), no en el diagrama global.
Errores por zona POS¶
Cada error capturado lleva el cod_terminal del request que lo originó: el TerminalAuthFilter lo pone en el MDC, el appender de Logback lo persiste en error_event.cod_terminal. GET /monitoring/errors agrega byTerminal (errores de las últimas 24 h agrupados por terminal; los que ocurren fuera de un request POS quedan como SIN_TERMINAL). El ErrorsPanel muestra las zonas con más errores y la lista filtrable por categoría (FISCAL, PAGO, TERMINAL_AUTH, VALE_ENVASE, DB, OTRO).
Paneles de la UI¶
Bajo cockpit-ui/src/panels/:
| Panel | Muestra |
|---|---|
ConversionPanel |
(nuevo) KPI de conversión (héroe), tendencia, motivos de no-completar, minutos al cancelar, fricción EAN. |
OverviewPanel |
Uptime y semáforos de subsistemas (señal real). |
BirdsEye |
Diagrama interactivo (ReactFlow); con "ver POS individuales" muestra tiles con device-health por terminal. |
TerminalsPanel |
Parque de POS (online/offline/nunca-visto/huérfano). |
TicketsPanel |
Tickets por estado, tendencia y drill-down por POS. |
CachesPanel |
Caches: tamaño, hit rate, estado y próximo refresh. |
ApiCallsPanel |
Top 50 endpoints (sin el tráfico propio del Cockpit). |
ErrorsPanel |
Errores por zona POS + lista filtrable por categoría. |
PaymentsPanel |
Conteos por backend de pago. |
FiscalPanel |
AFIP, CAEA, VOUCHERPENDING, reconciliador. |
JobsPanel |
Jobs @Scheduled con nombres amigables y estado color-coded (verde OK / rojo error). |
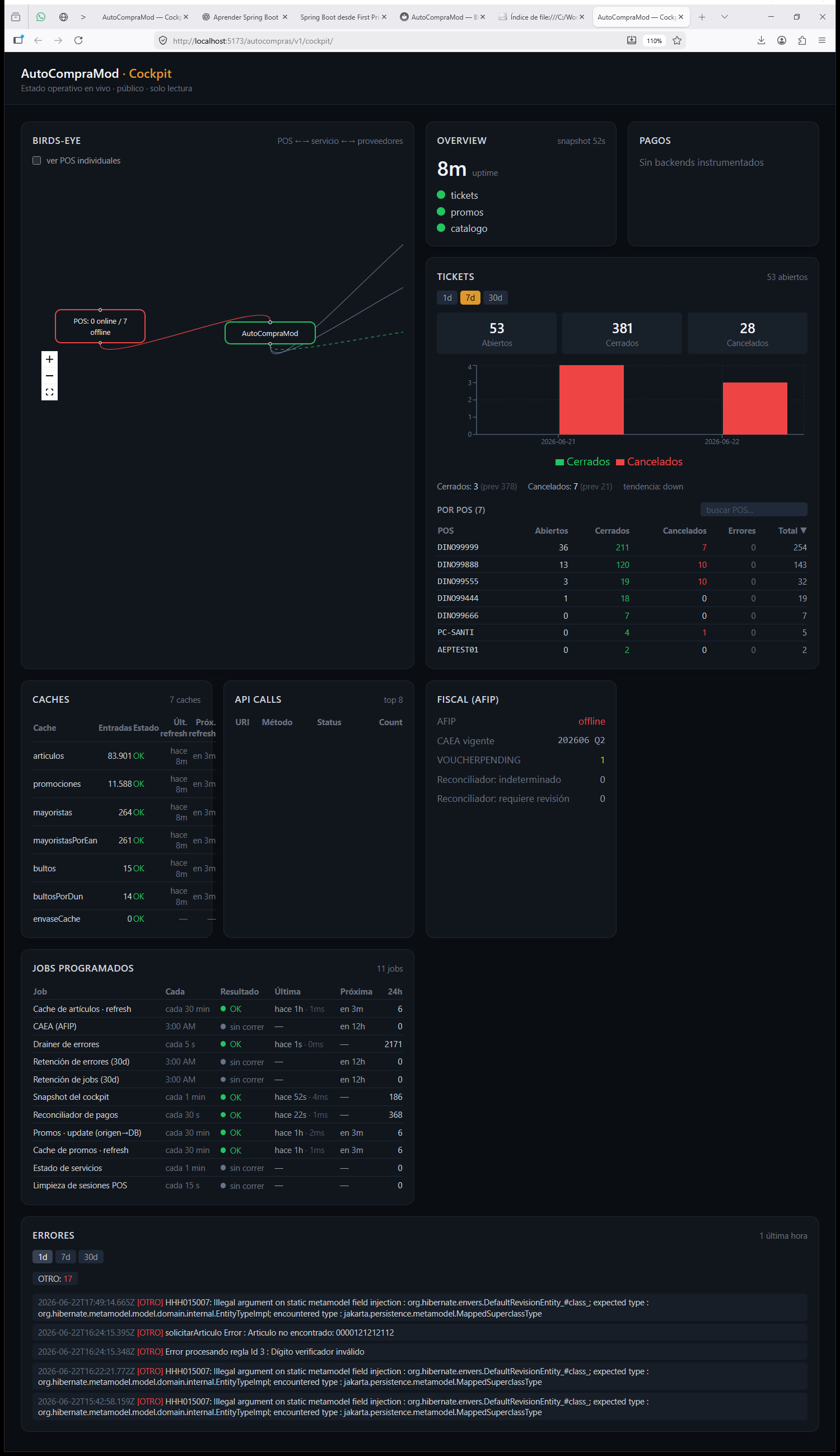
Los paneles inferiores (esta captura es previa al tema Binance-dark, pero el layout se mantiene): birds-eye, overview, tickets, caches (hit rate por cache), fiscal AFIP (CAEA, VOUCHERPENDING, reconciliador), jobs y el log de errores.
Generar carga para verlo en acción¶
El Cockpit muestra el estado, pero no genera carga. Para estresar el sistema y ver los paneles moverse (conversión, indeterminados drenando, latencias), está StressBench: 200 POS simulados vendiendo a la vez contra el backend real.
Si una terminal aparece offline
No significa que se borró: no pingeó dentro de la ventana de ~90 s, o está configurada pero nunca pingeó ("nunca visto"). Revisá su conectividad y su último heartbeat antes de asumir que está mal configurada.